我们有时候会有PDF转图片或是图片合成PDF的需求,尤其是一些扫描版的手稿、画册、字帖一类的的文档。
比如这里的视觉元素PDF图片,转换后可以放到相册里面临摹
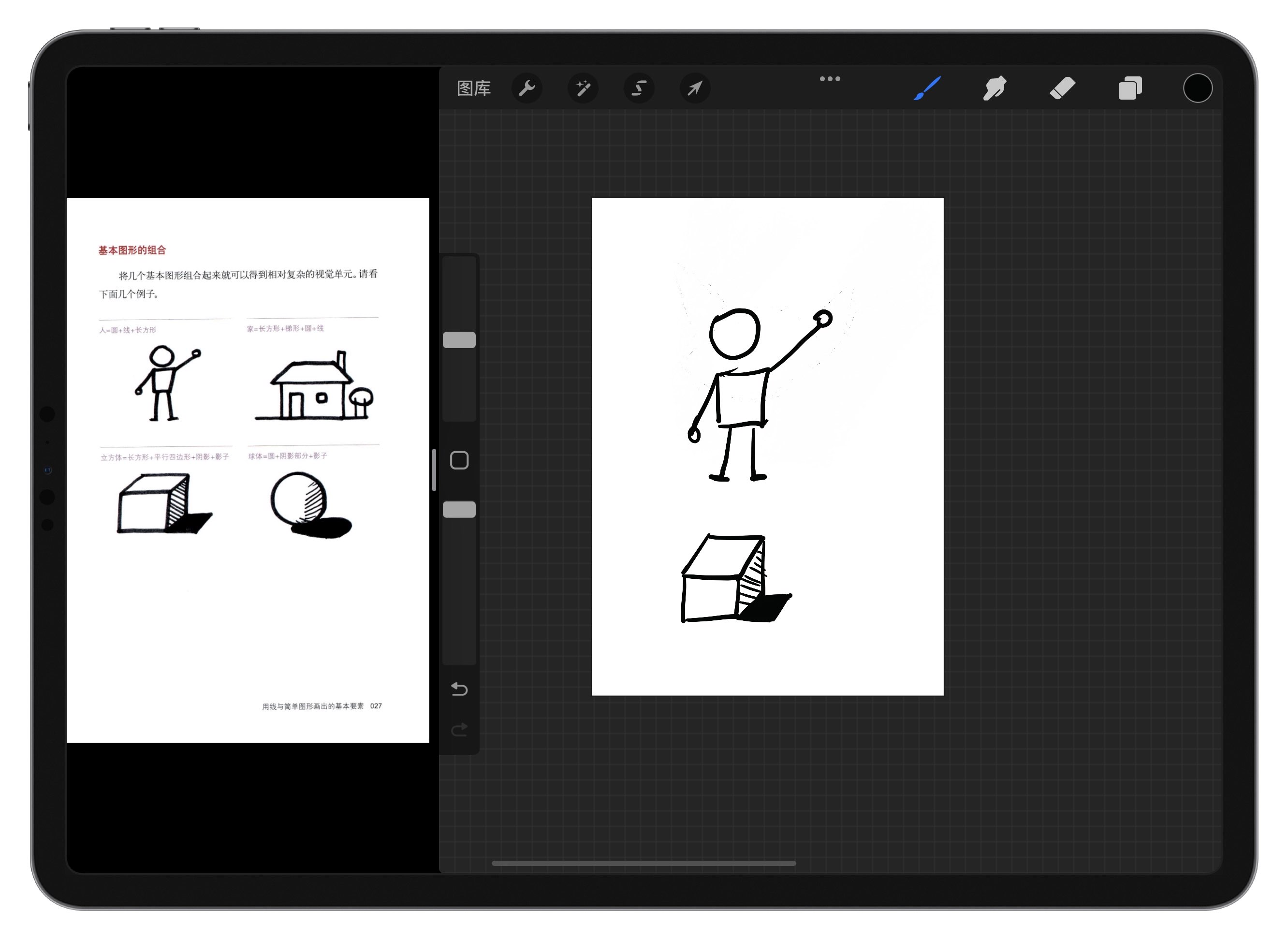
一般来说往往需要专门的软件,免费的有时候不好找,其实不用麻烦,使用Python编写一个几十行的小脚本就能实现,而且还不花钱,又能有成就感。
我们需要具备有一个Python环境,这点必须要有。这次我们转换PDF文档主要用到的是一个名叫PyMuPDF的PDF库,用到了里面的提取图片信息的方法fitz.open(file_relative_path)
话不多说,我们开始吧~
安装依赖库
我们先使用命令行安装python的依赖的PDF库
pip install PyMuPDF注意安装的版本,这里指定了xxx版本,如果不一致的话,你可以先卸载再安装
卸载的方法
pip uninstall PyMuPDF编写代码
接下来,我们要做的是指定一个要转换的PDF文件,定义一个变量file_relative_path来接收这个文件路径。
然后,获取PDF的所有页面,把每个页面通过for循环遍历处理,处理的过程就是保存当前页面为png格式的图像,这里为了方面记录,使用了一个count的变量计数,每次进行加一。
这里, pdf = fitz.open(file_relative_path)获取当前文件的所有页面,其中fitz是PyMuPDF库的一个工具,for page in pdf 遍历获取每个pdf中的页面
处理图片的过程中,里面有个涉及缩放的参数,默认的分辨率比较低,为了能够清晰的展示,这里进行了两倍的放大,这样即使是文字图片也能很清晰
zoom_x = 2 # (2-->1584x1224)
zoom_y = 2
mat = fitz.Matrix(zoom_x, zoom_y)
pixmap = page.get_pixmap(matrix=mat, alpha=False)最终代码如下:
import fitz
import os
def convert_pdf2img(file_relative_path):
"""
file_relative_path : 文件相对路径
"""
page_num = 1
filename = file_relative_path.split('.')[-2]
if not os.path.exists(filename):
os.makedirs(filename)
pdf = fitz.open(file_relative_path)
for page in pdf:
rotate = int(0)
# 每个尺寸的缩放系数为2,这将为我们生成分辨率提高4的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 2 # (2-->1584x1224)
zoom_y = 2
mat = fitz.Matrix(zoom_x, zoom_y)
pixmap = page.get_pixmap(matrix=mat, alpha=False)
pixmap.pil_save(f"{filename}/{page_num}.png")
print(f"第{page_num}保存图片完成")
page_num = page_num + 1
if __name__ =="__main__":
# 文件夹中文件名
file_relative_path = "2022.09.13重复重复再重复.pdf"
convert_pdf2img(file_relative_path)定义了一个单个参数的方法convert_pdf2img(file_relative_path),参数传递的是文件名,这里我们使用相对路径,意思是这个python脚本要和转换的文件放在一个文件夹里,像下面那样:
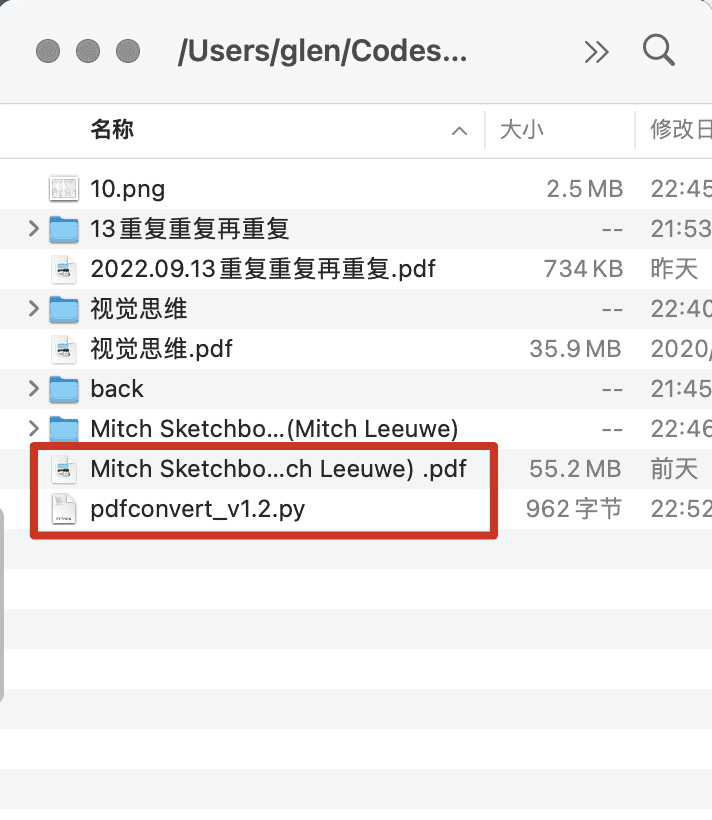
pdfconvert_v1.2.py是刚才python脚本的文件名,里面是上面的代码

怎么执行
这里为了方面转换,可以把要执行的PDF文档复制到脚本所在的文件,然后右键代码,选择在控制台执行,mac这块是terminal终端
如果要执行其他的pdf处理,可以把PDF复制进当前python脚本文件夹,这里可以在调用的时候更改一下变量的值为”xxx.pdf”就行了,xxx文档的名称
如file_relative_path = "视觉思维.pdf"
写Python脚本的建议,你可以使用记事本或是使用免费的编辑器,我这里使用的是免费开源的vscode,你可以网上搜索一下怎么安装使用。
代码执行
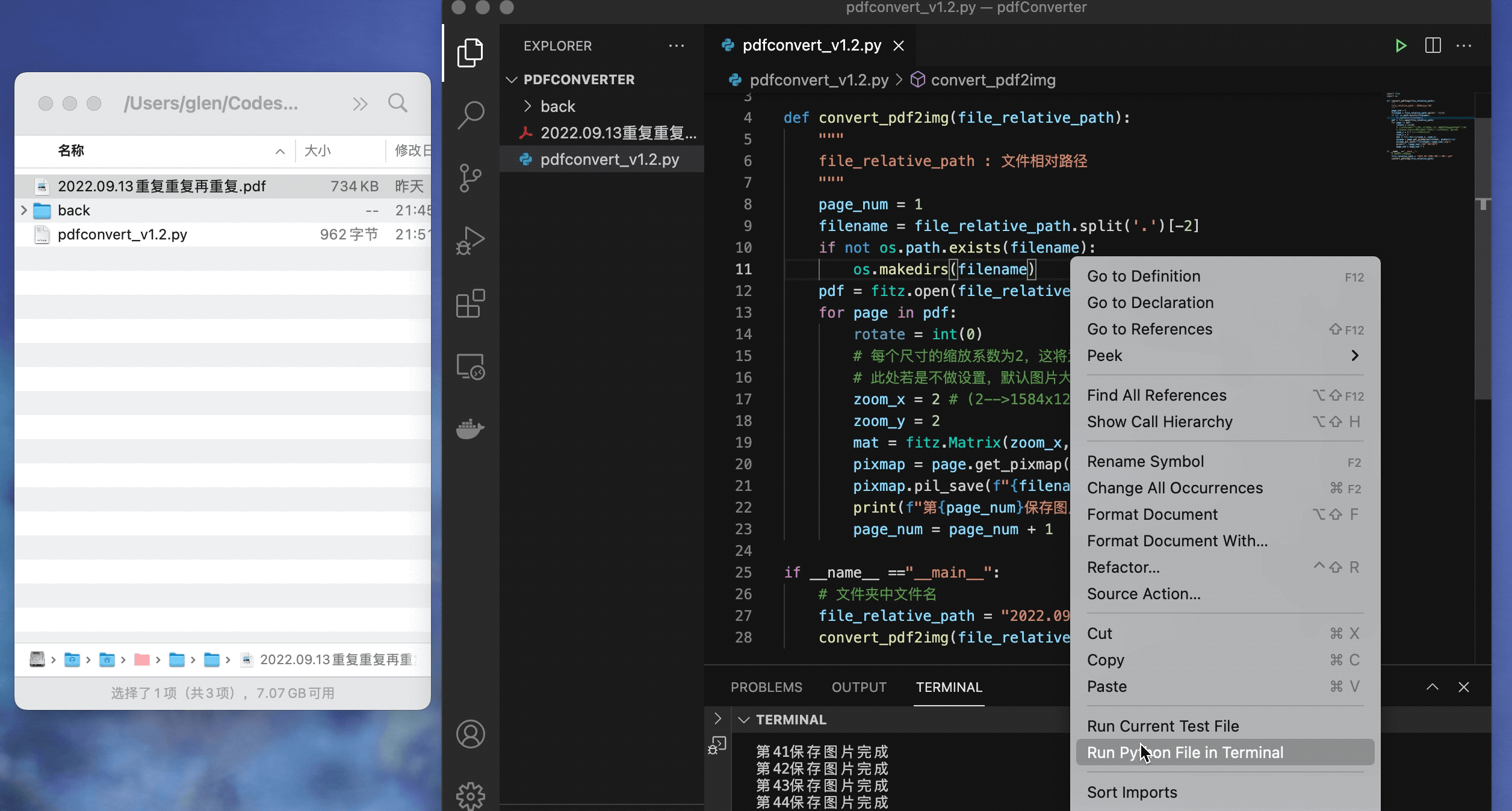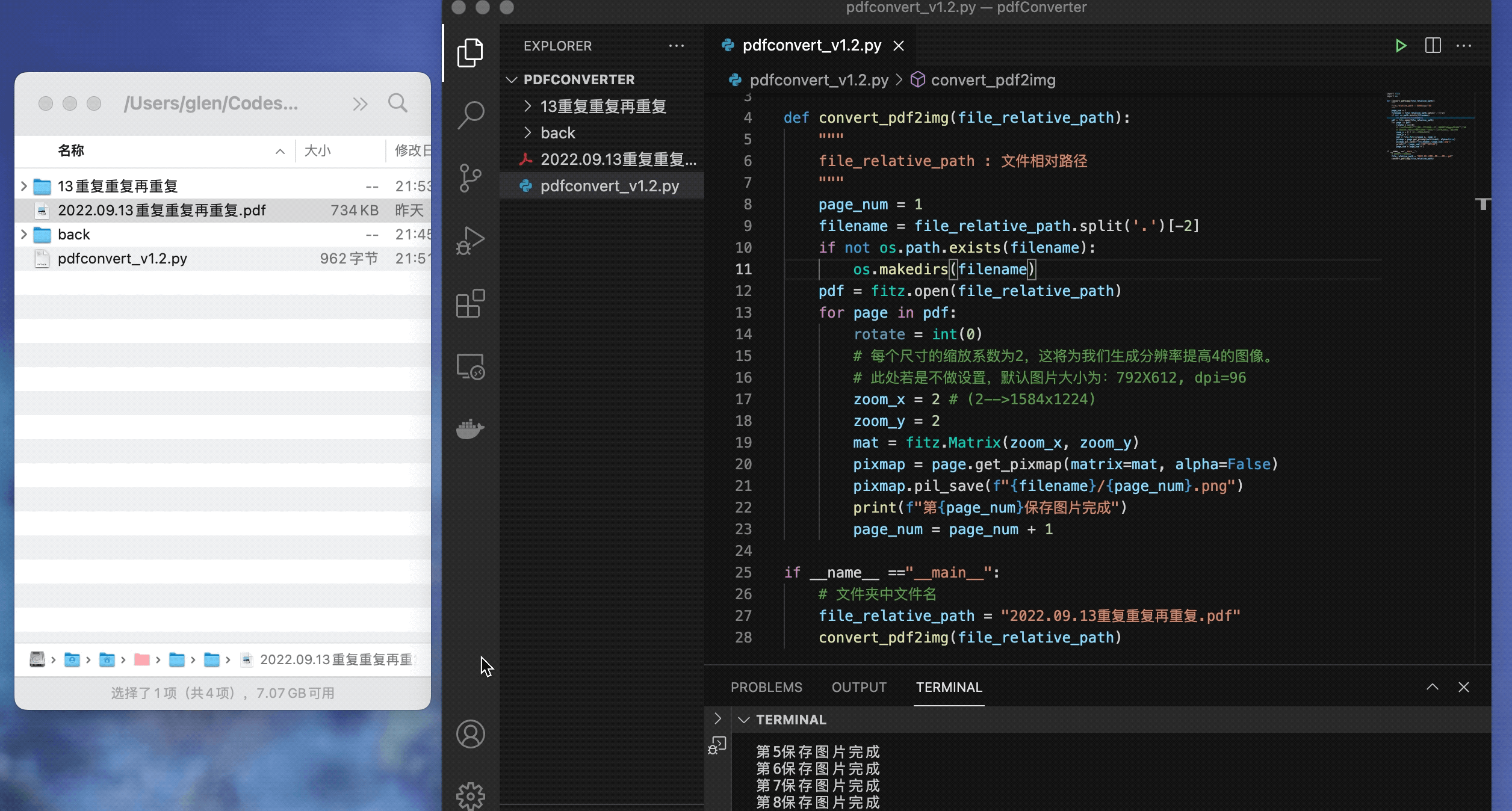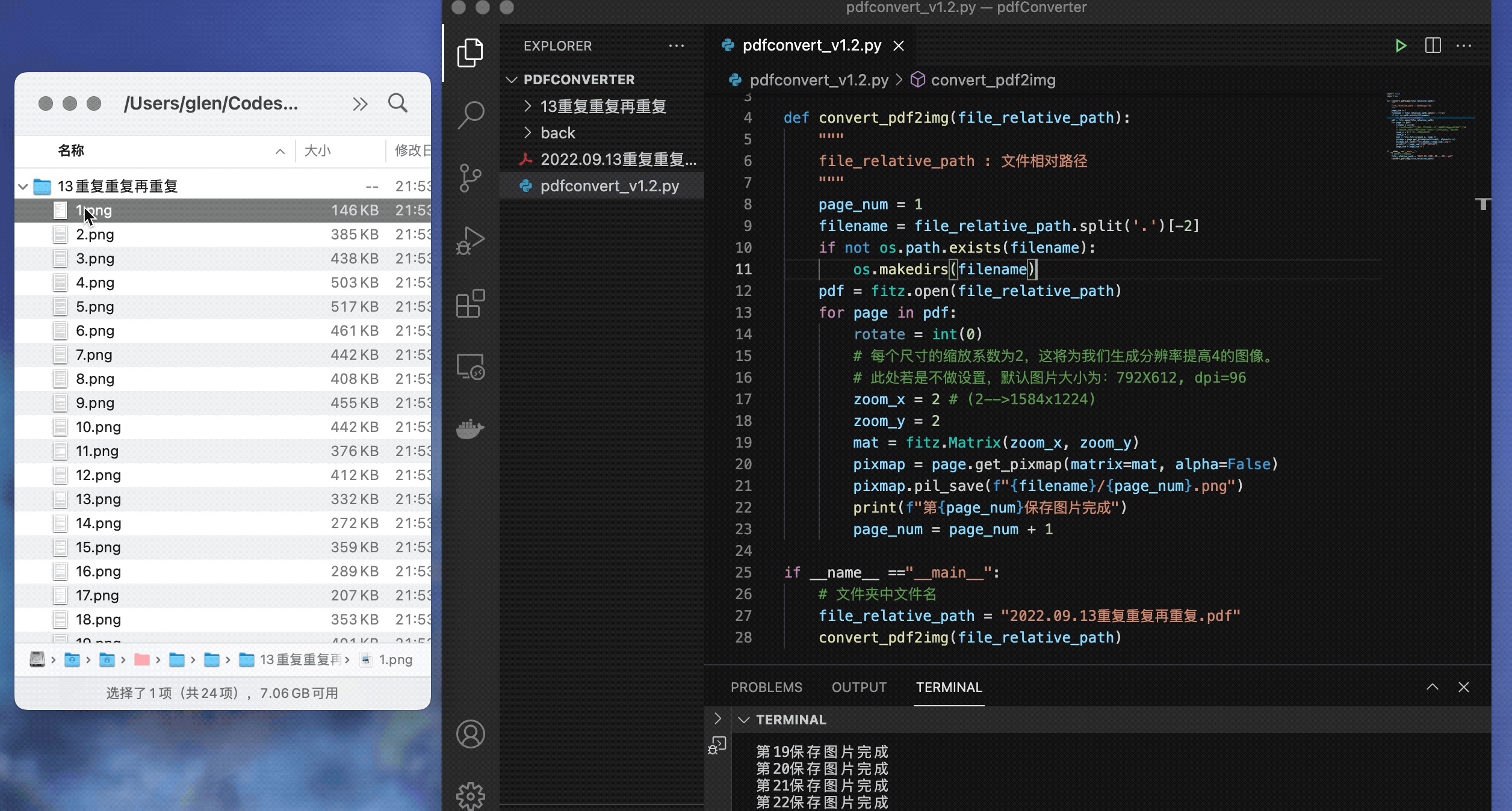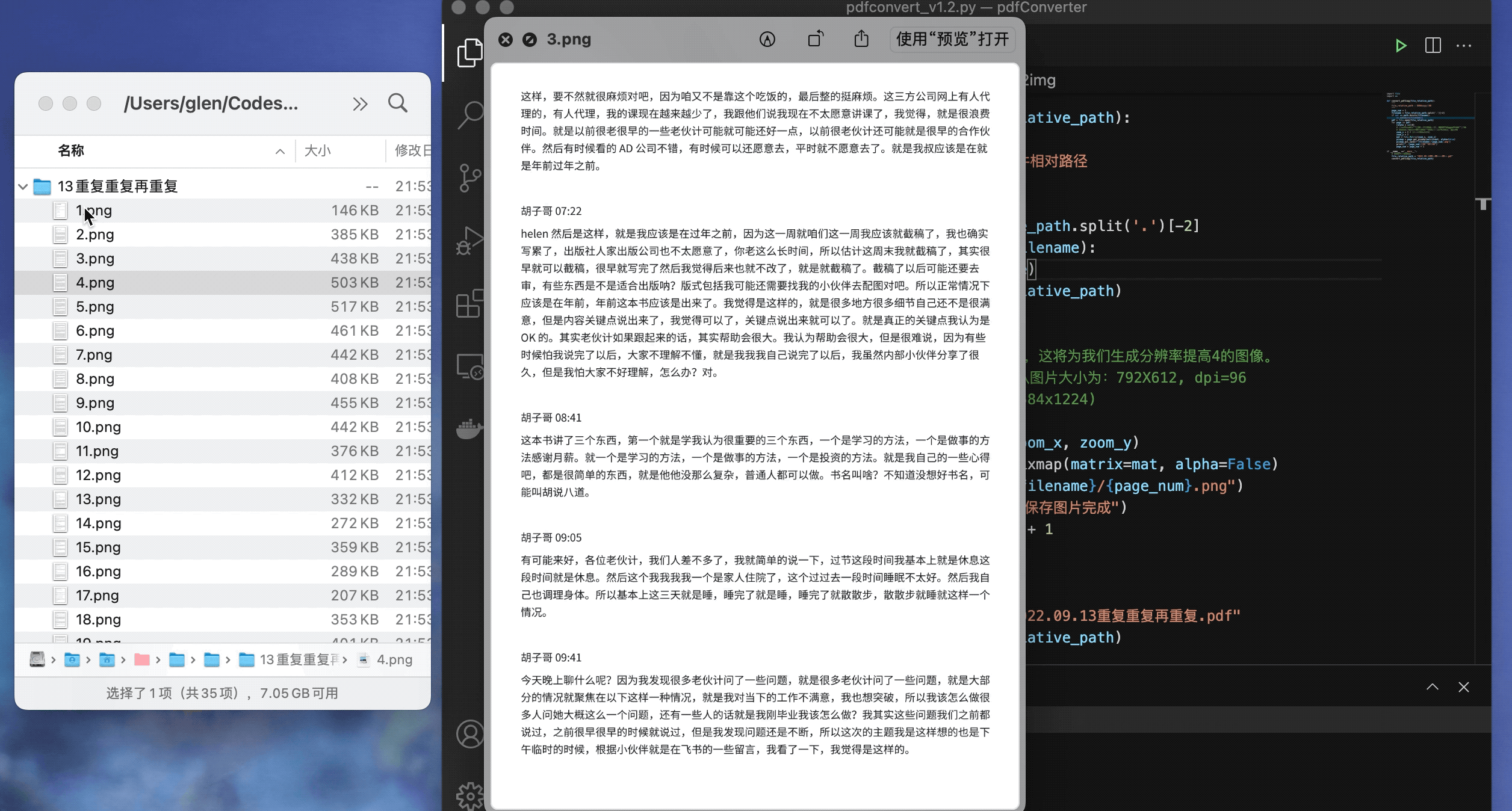
最终效果
1. 扫描版的PDF转换
这里是扫描版的手绘稿
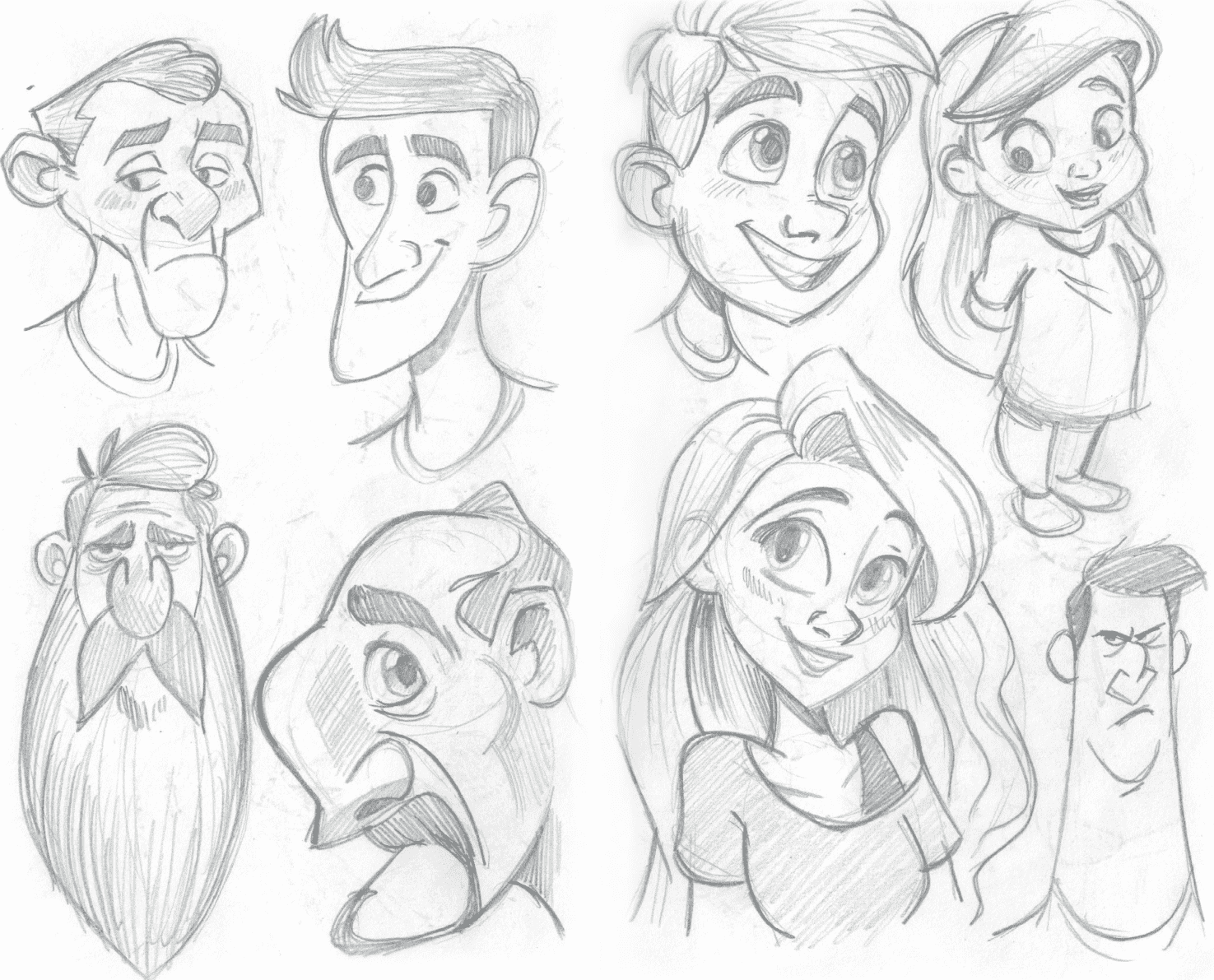
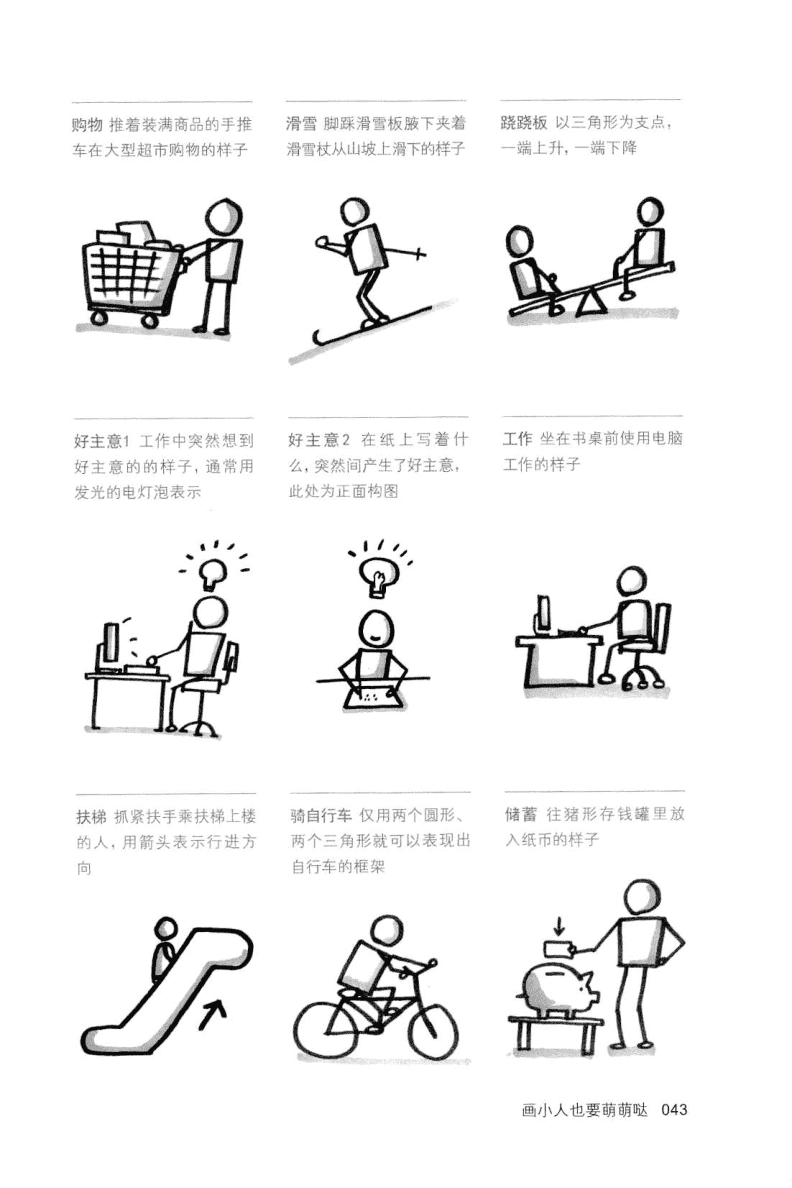
《视觉思维》里面的视觉元素:
2. 文字版PDF转换
这里是姜胡说的直播文稿PDF,也能够转换清晰的图片


