用Python实现公众号文章原汁原味剪藏

每当我们看到不错的公众号文章是不是都忍不住想收藏起来,但是收藏起来有不少问题,有些文章会过期或是被作者删除,我们再想看的时候就找不到了。用过印象笔记的同学都知道,印象笔记的剪藏功能很强大,能原汁原味的保留样式,今天我们介绍用Python实现公众号图片和文字的下载,并且可以原汁原味的访问。
之前看了用 Python 抓取公号文章保存成 HTML受到启发,同时也进行了改进,比如加入了异步协程下载的处理,对样式和相对路径进行改进,随有这篇文章。异步协程的使用可以参考Python 异步爬虫 aiohttp 示例,案例能够跑通,我们下面进入正题。
需要解决的问题
网页源码内容的下载
我们需要使用Python正确的访问文章地址,这里需要请求框架模拟正常的用户请求,需要设置请求头Header,如果没有的话可能就会被反爬处理获取不到正确的内容
网页图片和样式资源的下载
对于图片资源下载来说,要考虑效率问题,如果使用同步方式一张一张下载,只有等待前一张下载完成才能下载下一张,图片很多的话是必要花费很多时间。我们可以采用异步Http请求来实现,把网络资源请求的多个任务做成异步的,多张图片同时请求,然后统一等待下载结果,效率会大大提升。
网页的图片资源本地化替换
网页中不仅涉及到图片资源,还涉及到一些样式和Javascript相关的前端逻辑处理,如果不做本地化处理的话,可能一些样式会无法访问,比如文章格式居中或是代码块样式等。如下图,就是下载下来的网页代码样式丢失的,就是js等资源问题本地访问失败的情况
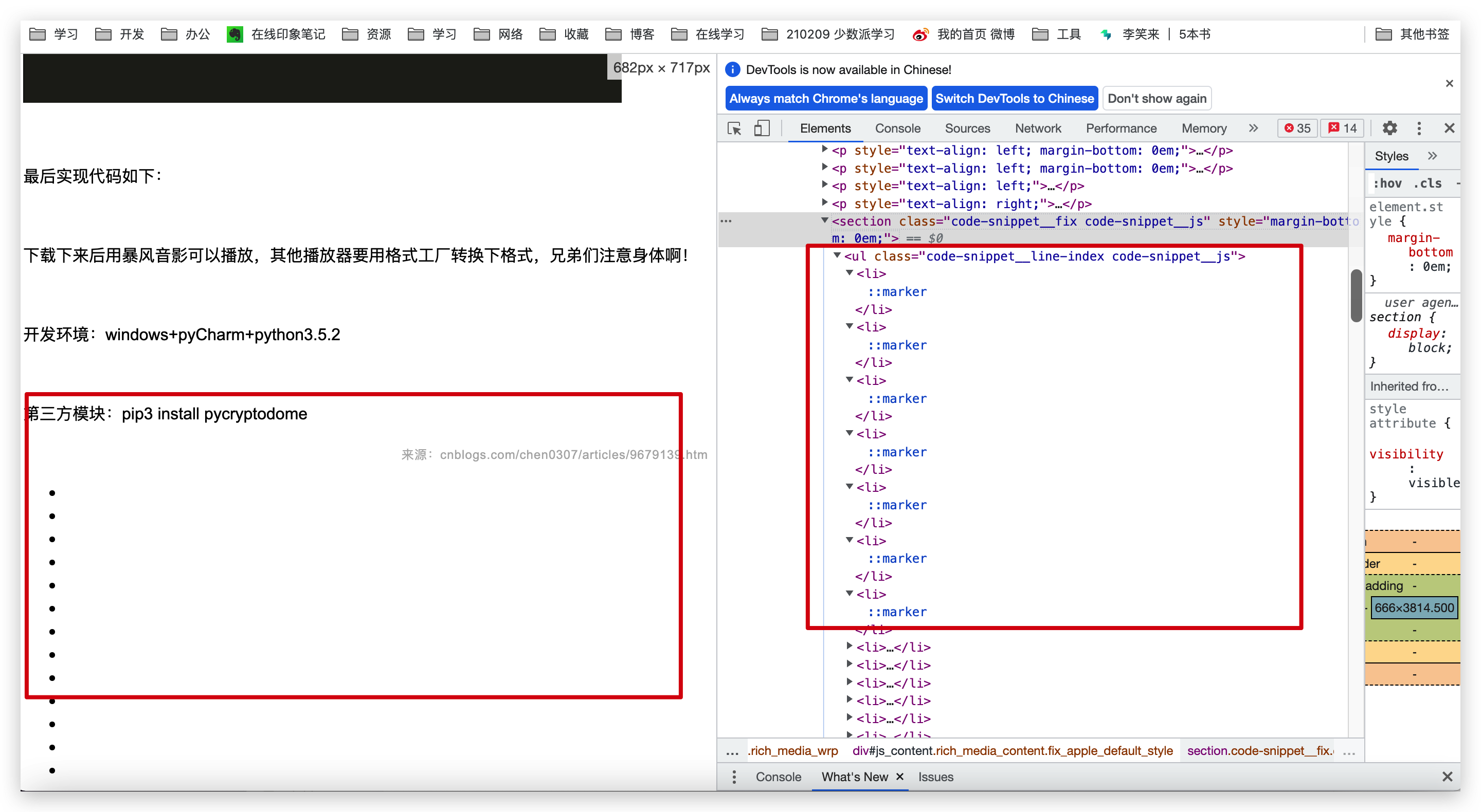
对于图片资源,由于网页中的图片是走的公众号平台的图床,往往有防盗链和访问限制,我们需要把网页源码中的图片资源链接替换成访问本地的地址,这里涉及到一些文本替换的逻辑。
功能实现
使用到的库依赖
这些需要提前使用pip提前安装好asyncio、aiohttp、BeautifulSoup4
import asyncio
import os
import time
import datetime
import re
import aiohttp
from aiohttp import TCPConnector
from bs4 import BeautifulSoup网页源码下载
这里定义一个异步async的get_html方法,用来获取指定url的网页文章的源码内容,用来异步Http请求网页文章html源码,使用BeautifulSoup解析html文档为xml结构,然后获取文章作者和头图信息和网页图片img标签信息。
async def get_html(url, save_dir, temp_filename):
"""
获取url文章内容html,并返回原图片地址
:param url 地址
:param save_dir 保存目录
:param temp_filename 临时文件名
:return:图片链接地址
"""
async with aiohttp.ClientSession(
headers=headers, connector=TCPConnector(ssl=False)) as session:
async with session.get(url) as resp:
text = await resp.text()
# 使用beautiful解析网页内容
soup = BeautifulSoup(text, 'lxml')
# 解析微信文章网页meta信息获取文章作者、头图等信息
article_infos = parse_wechat_article_info(soup, url)
# 文件名windows环境安全处理
filename = article_infos.get("title", temp_filename)
filename = get_safe_file_name(filename)
# 保存网页内容到本地
save_html(save_dir, text, filename)
# 获取网页中所有img标签
imgs = soup.find_all("img")
img_links = []
for img in imgs:
if 'data-src' in str(img):
img_links.append(img['data-src'])
elif 'src=""' in str(img):
pass
elif "src" not in str(img):
pass
else:
img_links.append(img['src'])
return img_links, text, article_infos, filename定义save_html函数,保存网页源码到本地
def save_html(save_path, html, name):
"""
保存html到本地
:param save_path: 保存地址
:param html: html文本内容
:param name: 保存名称
:return:, 'w'
"""
with open(os.path.join(save_path, name + '.html'), 'w', encoding='utf-8') as f:
f.write(html)
return html图片异步下载
这里定义异步的download_picfile下载图片文件,保存图片为jpeg格式。
首先对图片img标签中的data-src属性中的图片地址进行预处理,有些图片并不是以http://开头的绝对路径,而是相对路径和绝对路径的混合,为了能够正确请求,需要根据情况补充正确的图片地址。
对于每次处理后的原链接和下载到本地的保存链接,以字典{"old": pic_url, "new": image_file_abspath}的形式存储到old_new_links_dicts列表中,为后续替换为本地地址做准备。
async def download_picfile(pic_url, save_path, new_pic_name, old_new_links_dicts, image_dirname='images'):
"""
下载图片文件,保存图片到本地,并更新html的图片路径
:param pic_url: 图片路径
:param save_path:保存基地地
:param new_pic_name:保存名称
:return:
"""
# print("image_url:" + pic_url)
request_pic_url = ""
# 跟据文章的图片格式进行处理
if pic_url.startswith('//'):
request_pic_url = 'https:' + pic_url
# print('image_type: 不带请求协议头的路径的图片 url:', pic_url)
elif pic_url.startswith('/') and pic_url.endswith('gif'):
request_pic_url = base_image_url + pic_url
# print('image_type: pic 不带基础路径的图片 url:', pic_url)
elif pic_url.endswith('png') or pic_url.endswith('jpg') or pic_url.endswith('gif') or pic_url.endswith('jpeg'):
request_pic_url = pic_url
# print('image_type: png,jpg,gif,jpeg url:', pic_url)
else:
# 全路径的
request_pic_url = pic_url
# print('image_type: 其他类型图片 url:', pic_url)
async with aiohttp.ClientSession(
headers=headers, connector=TCPConnector(ssl=False)) as session:
async with session.get(request_pic_url) as resp:
text = await resp.read()
# 创建指定目录
save_image_path = os.path.join(save_path, image_dirname)
if not os.path.exists(save_image_path):
os.makedirs(save_image_path)
image_type = "jpeg"
new_pic_save_name = new_pic_name + "." + image_type
image_file_abspath = os.path.join(save_image_path, new_pic_save_name)
print('save picture... name:', new_pic_save_name)
with open(image_file_abspath, 'wb') as f:
f.write(text)
# 替换更新html地址,记录到字典列表里面
if old_new_links_dicts is not None:
old_new_links_dicts.append({"old": pic_url, "new": image_file_abspath})批量异步执行逻辑
主要的程序逻辑如下:
首先,获取loop执行第一个异步任务get_html获取links, html, article_info, article_filename这些信息
然后,根据返回的图片地址列表links,批量追加download_picfile下载图片任务到loop的异步执行的任务列表中
调用loop.run_until_complete()等待所有异步下载图片任务执行完毕
最后,调用update_htmlfile_imgs方法,把old_new_links_dicts存放的原远程图片地址和图片对应本地相对地址,对本地的网页html源码进行更新
# 异步循环处理
loop = asyncio.get_event_loop()
task = loop.create_task(get_html(link_url, base_path, base_picprefix))
# 获取文章task返回的信息,图片列表,网页的html文本,文章作者信息,处理后的文章标题
links, html, article_info, article_filename = loop.run_until_complete(task)
# 新的异步任务列,用来下载图片
tasks = []
old_new_links_dicts = []
# 构造图片存储文件名
index = 0
for link in links:
pic_name = base_picprefix + "_" + str(index)
tasks.append(download_picfile(link, base_path, pic_name, old_new_links_dicts))
index += 1
# 头图下载保存到html文件同路径,不记录到替换列表中
tasks.append(download_picfile(link, base_path, article_filename, None, ''))
# 批量执行并等待结果
loop.run_until_complete(asyncio.gather(*tasks))
# print("替换列表:", old_new_links_dicts)
# 执行完批量处理后,处理html的文本内容
update_htmlfile_imgs(base_path, article_filename, old_new_links_dicts)
end = time.time()
print(f'下载完成{index}个图片,用时:{end - start}秒')网页图片路径替换
这里对html文件中进行读取,对每一行的内容,进行图片新旧地址的替换。替换过程先打开源html文件,再写入一个temp文件,对后删除源html并重命名temp文件为源html文件
图片相对路径替换:由于不同系统的文件路径是不一样的,windows有磁盘分区,而Mac、Linux等Unix类型的系统是根路径/开头的,使用文件绝对路径会产生问题,这里就需要预先对old_new_links_dicts中的new的本地路径替换成image/xxx.jpeg的相对路径,统一保存到html中的img标签的src属性里
样式资源的替换:由于网页下载到了本地,资源链接很多都是写的相对地址,本地访问不到就会出现代码行和居中等样式问题,这里为了解决这个问题替换原来"src=\"//res"和"href=\"//res"相对资源开头地址,换成网络的https://res开头的地址,可以保证样式的处理
# 修改 HTML 文件,将图片的路径改为本地的路径
def update_htmlfile_imgs(html_path, html_file_name, old_new_links_dicts):
"""
更新html文件中的图片链接,并更换为相对的图片地址
:param html_path: html文件目录
:param html_file_name: 文件名
:param old_new_links_dicts: 要替换图片的字典list
:return:
"""
# 预处理相对路径链接,遍历其中的内容
for link_dict in old_new_links_dicts:
# print("dict:",link_dict)
# 处理列表中的字典dict,只替换new链接的value值
for key in link_dict.keys():
if key == 'new':
local_abs_path = link_dict.get(key)
# 此时获取的路径是绝对路径,绝对路径转换相对路径
new_relative_link = get_imgfile_relative_path(local_abs_path)
link_dict[key] = new_relative_link
# 打开两个文件,原始文件用来读,另一个文件将修改的内容写入
# 原始html
html_file_abs_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), html_path, html_file_name + '.html')
# 临时html文件
html_file_temp_abs_path = os.path.join(os.path.abspath(__file__), html_path, html_file_name + '_bak.html')
with open(html_file_abs_path, encoding='utf-8') as f, open(html_file_temp_abs_path, 'w', encoding='utf-8') as fw:
# 遍历每行,用replace()方法替换路径
for line in f:
# 优先替换图片路径
for i in range(0, len(old_new_links_dicts)):
link_map = old_new_links_dicts[i]
old_link = link_map.get("old")
new_relative_link = link_map.get("new")
line = line.replace(old_link, new_relative_link)
# 图片的img标签属性处理下,图片默认是data-src的,估计微信有处理
line = line.replace("data-src", "src")
# 再替换其他的常规资源路径,如js等
line = line.replace("src=\"//res", "src=\"https://res")
line = line.replace("href=\"//res", "href=\"https://res")
# 写入新文件
fw.write(line)
# 执行完,删除原始文件
os.remove(html_file_abs_path)
time.sleep(2)
# 修改新文件名为 html
os.rename(html_file_temp_abs_path, html_file_abs_path)
获取网页文章名保存
这里需要分析提取公众号文章的作者和标题信息,都放在meta标签里面,所以需要提取meta标签中的元素,如图:
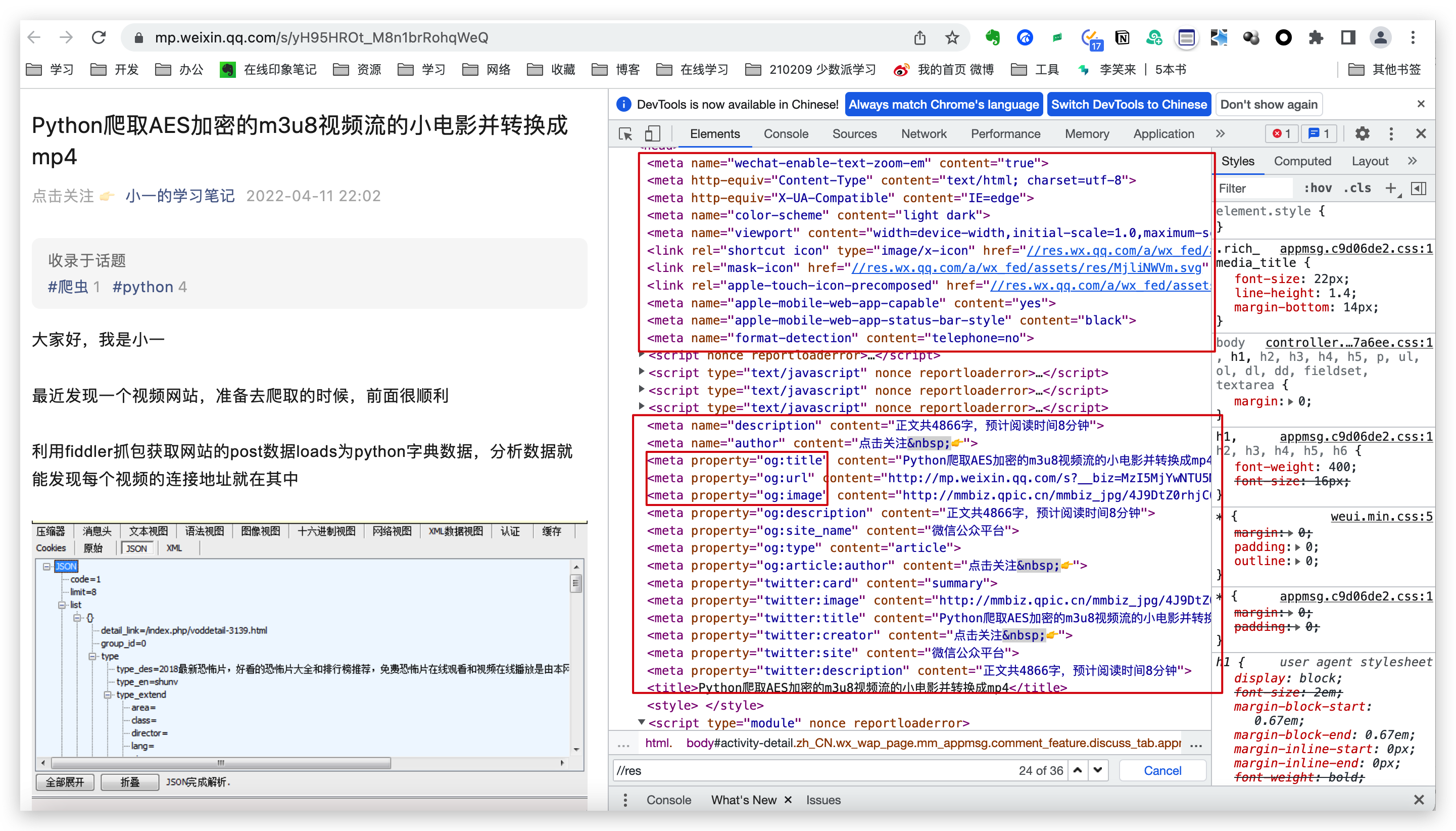
处理逻辑如下:
def parse_wechat_article_info(xml_bssoup, link_url):
"""
解析微信微信文章基本信息:作者,标题,摘要,文章头图
:param xml_bssoup: beautifulSoup解析的网页html的对象
:param link_url: 微信文章链接地址
:return:
"""
# 标题,作者,链接,头图,描述
title = ''
author = ''
link = link_url
head_image = ''
desc = ''
# 非公众号文章通用处理
if link_url.find("mp.weixin.qq.com") == -1:
print('非微信公众号文章 url:%s' % link_url)
if xml_bssoup.title_name is not None:
print(xml_bssoup.title_name.string)
title = xml_bssoup.title_name.string
# 遍历meta标签获取,properties属性,meta标签有property和content两个属性,相当于key和value
meta_list = xml_bssoup.find_all('meta')
# print("meta_list:", meta_list)
for meta in meta_list:
if str(meta.attrs).find('property') != -1:
# 获取property属性值
prop_value = meta['property']
# 标题
if prop_value == 'og:title':
title = meta['content']
# 作者
if prop_value == 'og:article:author':
author = meta['content']
# 文章头图
if prop_value == 'og:image':
head_image = meta['content']
# 描述
if prop_value == 'og:description':
desc = meta['content']
# 文章描述
if str(meta.attrs).find('name=') != -1:
# 获取property属性值
name_value = meta['name']
if name_value == 'description':
desc = meta['content']
if name_value == 'author':
author = meta['content']
# title, author, link, head_image, desc = ''
article_dict = {
"title": title,
"author": author,
"link": link,
"head_image": head_image,
"desc": desc}
# 遍历其中的内容
print("文章信息:", article_dict)
return article_dict程序执行结果验证
好了,上面就是将文章页面和图片下载到本地的代码,接下来我们再Idea上运行一下 ,程序开始执行,打印日志如下:
可以看到,文章中的6张图片总下载时长是2.6秒,已经很快了
/opt/anaconda3/bin/python "/Users/glen/Nutstore Files/vscodeSpace/python/wechat_article_downloader.py"
文章信息: {'title': '用 Kindle + KindleMate + Anki + Economist 打造完美英语学习系统', 'author': '刘志新', 'link': 'https://mp.weixin.qq.com/s/HgwOO5RUT7BtZuNBuokwqw', 'head_image': 'http://mmbiz.qpic.cn/mmbiz_jpg/BBXrCicxMgHtPnR9ibVozdq1rUCl3gVhJ6HCDs6Pg2kmGe6FOicgSJbyya0boE4OH3icy5HUT4I3rH07ELibxwsZrvA/0?wx_fmt=jpeg', 'desc': '英语不是学的,而是用的'}
save picture... name: 20220417223340406126_4.jpeg
save picture... name: 用 Kindle + KindleMate + Anki + Economist 打造完美英语学习系统.jpeg
save picture... name: 20220417223340406126_2.jpeg
save picture... name: 20220417223340406126_5.jpeg
save picture... name: 20220417223340406126_0.jpeg
save picture... name: 20220417223340406126_1.jpeg
save picture... name: 20220417223340406126_3.jpeg
下载完成6个图片,用时:2.6417782306671143秒
我们去程序存放的目录,就能看到下载下来的文章和图片,图片文件统一放到images文件夹中,网页文件html在 images同级目录

这里把文章信息中的头图也按照文章名同名保存下来了
访问具体的html可以看文章信息,代码样式也正常展示了
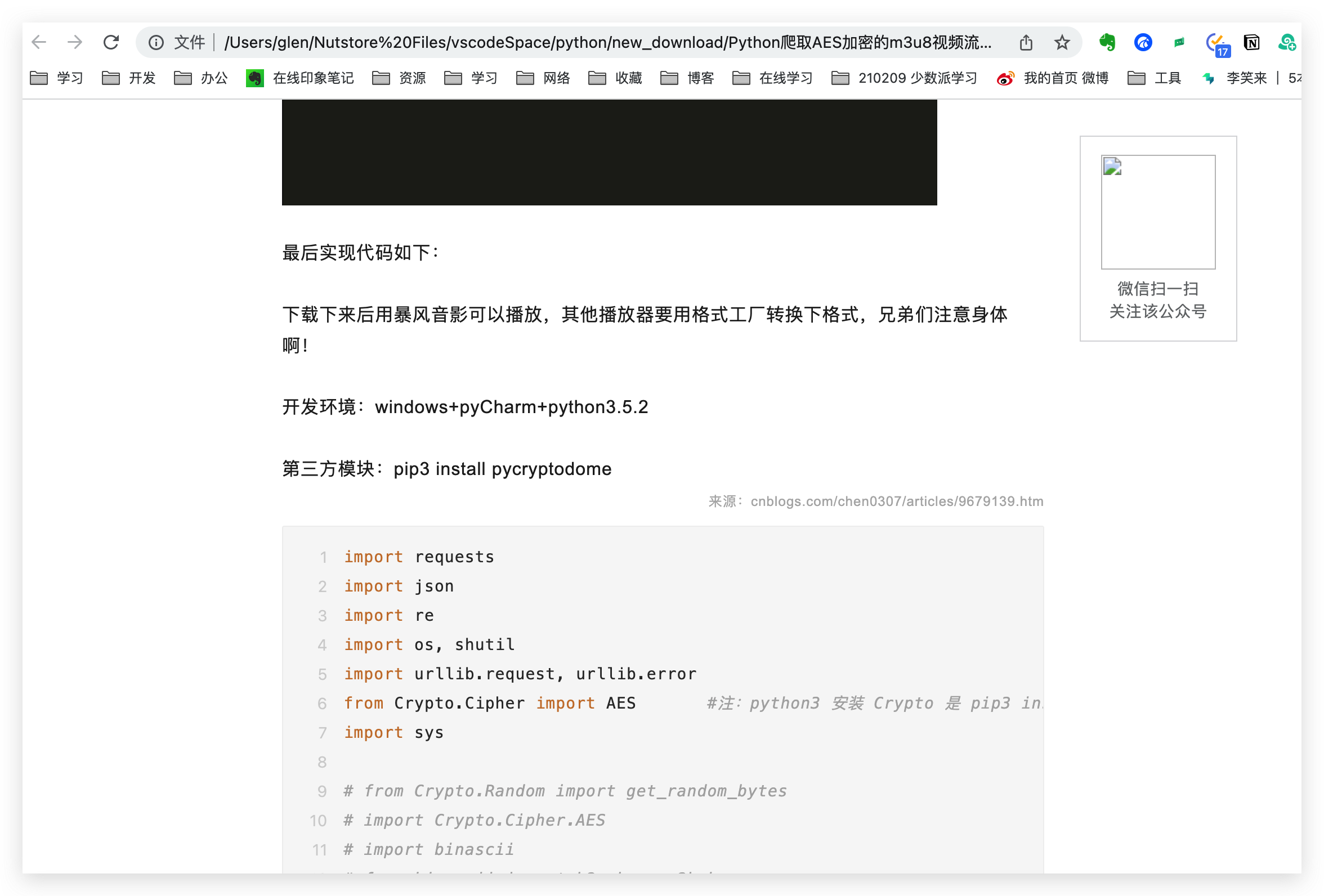
Mac上的html文件图片,也换成了本地的相对路径
总结
本文为大家介绍了如何通过 Python 将公号文章原汁原味下载到本地,并保存为 HTML 和图片,这样就能实现文章的离线浏览了。当然如果你想将 HTML 转成 PDF 也很简单,直接用 pdfkit.from_file(xx.html,target.pdf) 方法直接将网页转成 PDF,而且这样转成的 PDF 也是带图片的。
展望,后续可以基于此方案做扩展,比如加入GUI界面,实现多篇文章的批量下载,或者是封装成下载模块,给web的API接口使用,接入机器人如Hubot,使用IM聊天工具发送文章链接给bot机器人,机器人执行脚本或是服务进行文章的下载等。
这是我写的第一篇正式的技术文章,请多多大家指教,欢迎关注点赞分享
【**代码**获取方式****】
章鱼的学习探索公众号,回复:220417

